

Whenever I’m analysing the performance of a SQL Server database, I often find myself needing to retrieve a list of all indexes for review.
Missing or unsuitable indexes are a leading cause of SQL Server slowdowns, so it can be very useful to view the existing indexes to get an idea of how heavily indexed or not a particular database currently is.
Having a SQL query that can display the details of all indexes, such as the index name and index columns, along with other helpful information such as the related table or view name can be an invaluable resource.
In this article, I am going to look at such a query and show an example of the kind of results that it produces.
The Query
Let’s jump straight into the query which I’ve included in the sub-section below.
The query source is also included in my SQL Server Scripts GitHub repository, along with other useful SQL scripts.
SQL
The SQL query has been adapted to display the most important information in what I believe is the most relevant order.
-- Example of how to list all indexes in a database. SELECT SCHEMA_NAME(o.[schema_id]) + '.' + o.[name] AS [Table/View Name], i.[name] AS [Index Name], SUBSTRING(key_column_names, 1, LEN(key_column_names) - 1) AS [Index Key Columns], ISNULL(SUBSTRING(included_column_names, 1, LEN(included_column_names) - 1), '') AS [Included Columns], CASE WHEN i.[type] = 1 THEN 'Clustered Index' WHEN i.[type] = 2 THEN 'Non-Clustered Unique Index' WHEN i.[type] = 3 THEN 'XML Index' WHEN i.[type] = 4 THEN 'Spatial Index' WHEN i.[type] = 5 THEN 'Clustered Columnstore Index' WHEN i.[type] = 6 THEN 'Non-Clustered Columnstore Index' WHEN i.[type] = 7 THEN 'Non-Clustered Hash Index' END AS [Index Type], CASE WHEN i.is_unique = 1 THEN 'Yes' ELSE 'No' END AS [Unique], CASE WHEN o.[type] = 'U' THEN 'Table' WHEN o.[type] = 'V' THEN 'View' END AS [Object Type] FROM sys.objects o INNER JOIN sys.indexes i ON o.[object_id] = i.[object_id] CROSS APPLY( SELECT c.[name] + ', ' FROM sys.index_columns ic INNER JOIN sys.columns c ON ic.[object_id] = c.[object_id] AND ic.column_id = c.column_id WHERE ic.[object_id] = o.[object_id] AND ic.index_id = i.index_id AND ic.is_included_column = 0 order by key_ordinal FOR XML PATH ('')) A (key_column_names) CROSS APPLY( SELECT c.[name] + ', ' FROM sys.index_columns ic INNER JOIN sys.columns c ON ic.[object_id] = c.[object_id] AND ic.column_id = c.column_id WHERE ic.[object_id] = o.[object_id] AND ic.index_id = i.index_id AND ic.is_included_column = 1 ORDER BY index_column_id FOR XML PATH ('')) B (included_column_names) WHERE o.is_ms_shipped <> 1 AND i.index_id > 0 AND i.is_primary_key = 0 ORDER BY o.[name], i.[name]
A fair bit is going on in this query, so I’ll explain it further in the following sub-section.
Breakdown
Let’s break down the details of what is returned by the above query.
Table/View Name
The first column returned is the name of the table or view that the index is associated with. The schema and name of the table/view are selected from the sys.objects table.
I find that having this column listed first is best for the scenarios I most commonly use the query for. Usually, I’m trying to identify if the indexes that I’m expecting to exist on certain tables are already there, or if I need to consider dropping existing indexes on a specific table and craft some better ones.
Index Name
The name of the index is selected from the sys.indexes table. Of course, this column is very important for identifying each index that is returned. I find that the index name naturally sits well alongside the table/view name for context.
Index Key Columns
The columns that make up the index key are displayed next in a comma-separated fashion. The name of each column is selected from the sys.columns table which is joined to the sys.index_columns table within the CROSS APPLY near the end of the query. The key columns are identified by filtering on the is_included_column column where the value is 0.
Included Columns
In the same manner as the index key columns, the included columns are displayed in comma-separated format. The sub-query within the CROSS APPLY is almost identical to the sub-query for the index key columns, except that the filtering on the is_included_column column is changed to filter where the value is 1.
Index Type
It can be useful to know the type of the index. The index type is determined by selecting it from the sys.indexes table. In most cases, this will either be ‘Clustered Index’ or ‘Non-Clustered Unique Index’.
Unique
It can also be useful to know whether the index has been configured as a unique index. This is determined in the query by returning either ‘Yes’ or ‘No’ depending on the value of the is_unique column on the sys.indexes table.
Object Type
If you have lots of views in your database (in addition to tables) it can be helpful to see what type of object the index is associated with. If this is the case you may find it more useful to see the object type as one of the first columns in the query rather than being the last. The type of object is displayed as either ‘Table’ or ‘View’ depending on the value of the type column on the sys.objects table.
Filtering and ordering
The WHERE clause near the end of the query excludes Microsoft objects and checks the index ID.
In addition to the above filters, any primary key indexes are excluded. In some scenarios, you may need to see the primary keys, as missing primary keys can cause big performance problems. Feel free to remove this clause if you suspect that this may be the case when analysing your database.
If you are running the query against a replicated database, you may find that the results are cluttered with replication-specific indexes, with names similar to the following.
MSmerge_index_19564342454
In these cases, you can add another condition to the WHERE clause to exclude these. For example, for a database that is set up for Merge Replication, you can add the following.
AND i.name NOT LIKE 'MSMerge_index_%'
Other than the index name prefix (i.e. ‘MSMerge_index_’) there isn’t any other index property we can filter on to exclude replication indexes.
The records returned by the query are ordered first by the table/view name, and then by the index name.
Feel free to adjust the ordering to whatever makes the most sense to you. For example, you could also order by the type of index or simply order on the index name itself.
The Results
After running the query the results should be similar to the following screenshot, albeit with records that are relevant to the tables/views and indexes that are in your particular database.
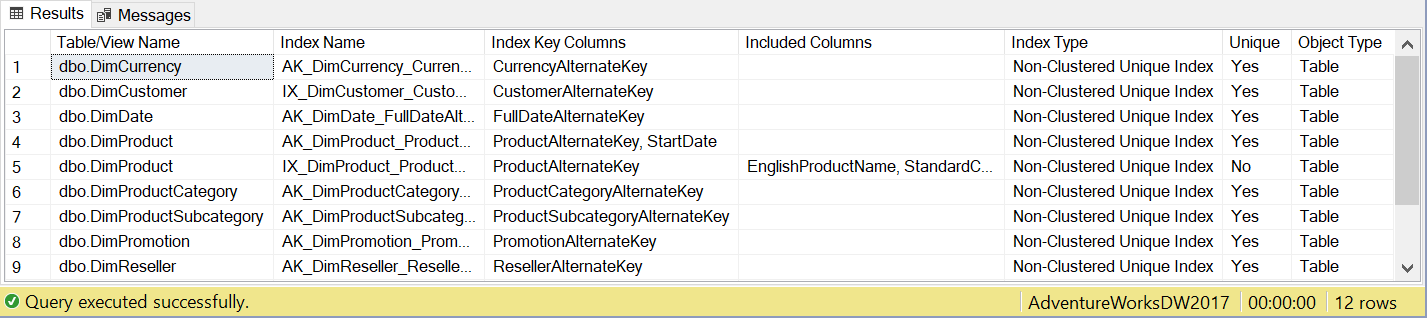
The above results are from a slightly modified version of the sample AdventureWorks database.
I’ve reduced the width of the columns so that they all fit into the Results pane within SQL Server Management Studio. However, as you can see from the output of the query, the well-named headings and the ordering that has been applied produce a highly readable set of results.
Summary
In this article, I’ve shown you a query that can be used to list all indexes in a SQL Server database.
I’ve walked through the details of what is returned by the query and discussed how the records are filtered and ordered.
Lastly, I’ve demonstrated what the results look like in a sample database.
Comments