

Sometimes duplicate data can make its way into a database, whether it be due to a software defect or as the result of an error that one or more users have made.
Regardless of the cause, you may find yourself in a position where you need to find and delete duplicate records from a database. Usually, the requirements for the deletion of the data will be based on some criteria where records should be deleted when particular columns have the same value.
In this post, I will share a specific approach you can take to find and delete duplicate records from a SQL Server (or Azure SQL) database using T-SQL.
Setting up the environment
Before jumping into the solution, let me take a moment to explain the environment that I’ll be using to demonstrate the approach.
Tools
Regarding tools, I’m using SQL Server 2022 Developer Edition as the database engine and SQL Server Management Studio (SSMS) 19 as the tool for running queries and inspecting the results.
For the database, I’m working with the Adventure Works Data Warehouse (2022 version).
Data
To set up the test data, I’m going to add some duplicate records to the ‘dbo.DimOrganization’ table within the ‘AdventureWorksDW2022’ database.
If I select everything from the ‘dbo.DimOrganization’ table after doing a fresh restore of the ‘AdventureWorksDW2022’ database, this is what I can see in the Results pane within SSMS.
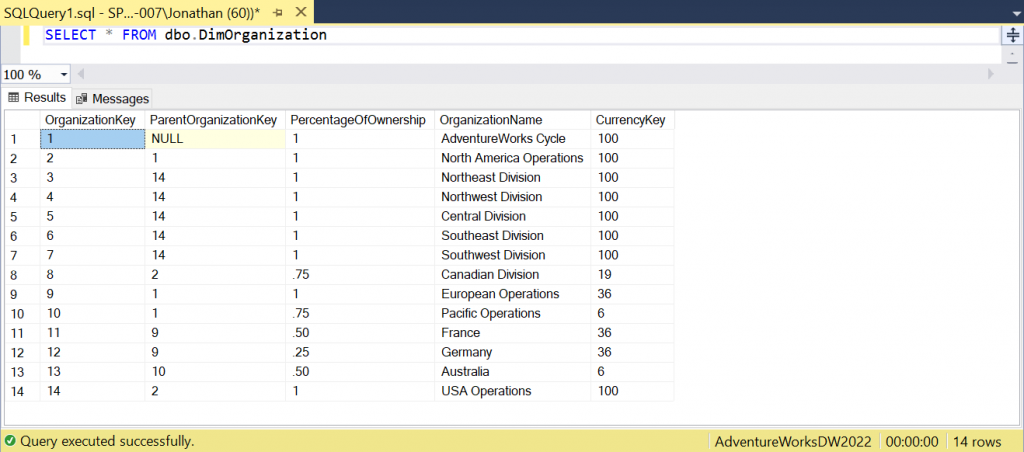
Next, I’m going to add some records containing duplicate data using the SQL below.
INSERT INTO dbo.DimOrganization (ParentOrganizationKey, PercentageOfOwnership, OrganizationName, CurrencyKey) VALUES (1, 1, 'Acme', 100) INSERT INTO dbo.DimOrganization (ParentOrganizationKey, PercentageOfOwnership, OrganizationName, CurrencyKey) VALUES (1, 2, 'Acme', 100) INSERT INTO dbo.DimOrganization (ParentOrganizationKey, PercentageOfOwnership, OrganizationName, CurrencyKey) VALUES (NULL, 3, 'Acme', 100)
Note that the ‘OrganizationName’ and ‘CurrencyKey’ have been assigned the same value in all 3 cases above, but the other values vary in some or all cases intentionally.
If I now select everything from the ‘dbo.DimOrganization’ table, these are the new results.
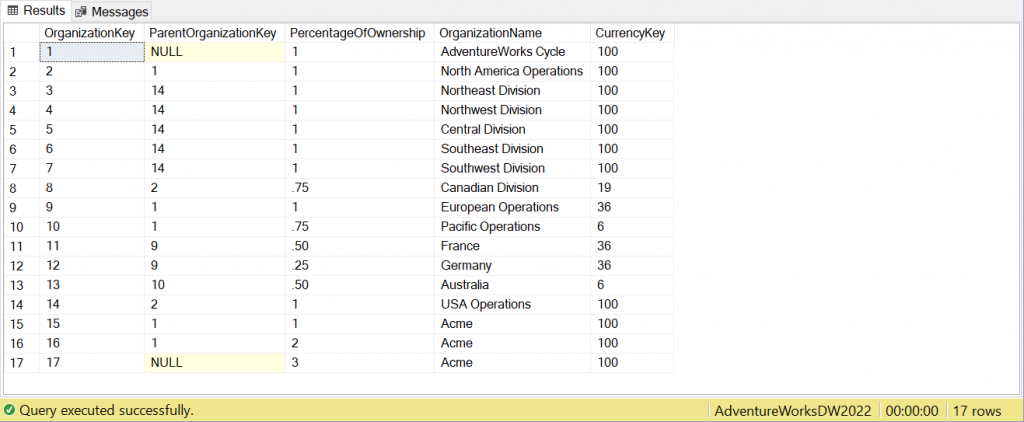
Rows 15, 16 and 17 are the newly added rows. Now that there is some duplicate data in place, let’s move on to seeing how we can identify the duplicate records.
Finding duplicate records
For the purposes of this article, I will consider any records in the ‘dbo.DimOrganization’ table that have the same ‘OrganizationName’ and ‘CurrencyKey’ to be duplicates, even though other columns such as ‘PercentageOfOwnership’ have different values.
The SQL below can be used to identify duplicate records in the ‘dbo.DimOrganization’ table.
WITH Organizations AS ( SELECT ROW_NUMBER() OVER (PARTITION BY OrganizationName, CurrencyKey ORDER BY OrganizationKey) AS RowNumber, * FROM dbo.DimOrganization ) SELECT * FROM Organizations WHERE RowNumber > 1;
The SQL query uses the WITH keyword to create a temporary data set that we can work with. Within the body of the WITH clause, the ROW_NUMBER function is used along with the OVER clause and the PARTITION BY value expression to group the rows by the ‘OrganizationName’ and ‘CurrencyKey’ columns, ordered by the ‘OrganizationKey’ column.
The asterisk is used to select all columns from the ‘dbo.DimOrganization’ table and the final SELECT selects everything from the ‘Organizations’ data set where the ‘RowNumber’ is greater than 1 to identify the duplicate records that need to be deleted.
After running the query, the results look like the following screenshot from SSMS.
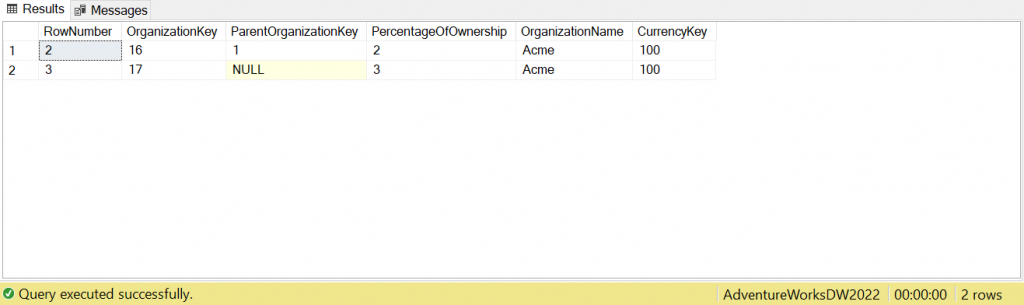
The query results clearly show us what needs to be deleted from the database, with the ‘RowNumber’ visible, along with all of the other data from the table for reference.
Deleting the duplicates
To delete the duplicate records, the query from the previous section needs to be altered slightly, as follows.
WITH Organizations AS ( SELECT ROW_NUMBER() OVER (PARTITION BY OrganizationName, CurrencyKey ORDER BY OrganizationKey) AS RowNumber
FROM dbo.DimOrganization ) DELETE FROM Organizations WHERE RowNumber > 1;
Note that it is vitally important when modifying the above SQL script to suit your needs to make sure you are completely confident that the script is correct and that it will delete the correct data. It is advisable to take backups of your database before executing the deletion as a safety measure.
The only changes to the query are removing the comma and asterisk after the ‘RowNumber’ column (since we don’t need to view any columns from the table we are targeting) and changing the SELECT * to DELETE on the last line.
If there is a need to do some other data clean-up actions at the same time in a transactional manner, a simple SQL transaction can be added along with the additional action(s), as shown below (an UPDATE statement in this case).
BEGIN TRAN; WITH Organizations AS ( SELECT ROW_NUMBER() OVER (PARTITION BY OrganizationName, CurrencyKey ORDER BY OrganizationKey) AS RowNumber FROM dbo.DimOrganization ) DELETE FROM Organizations WHERE RowNumber > 1; UPDATE dbo.DimOrganization SET ParentOrganizationKey = 1 WHERE ParentOrganizationKey IS NULL AND OrganizationKey > 1; COMMIT TRAN;
In either case, the results returned when selecting everything from the ‘dbo.DimOrganization’ table after executing the deletion will now look as follows.
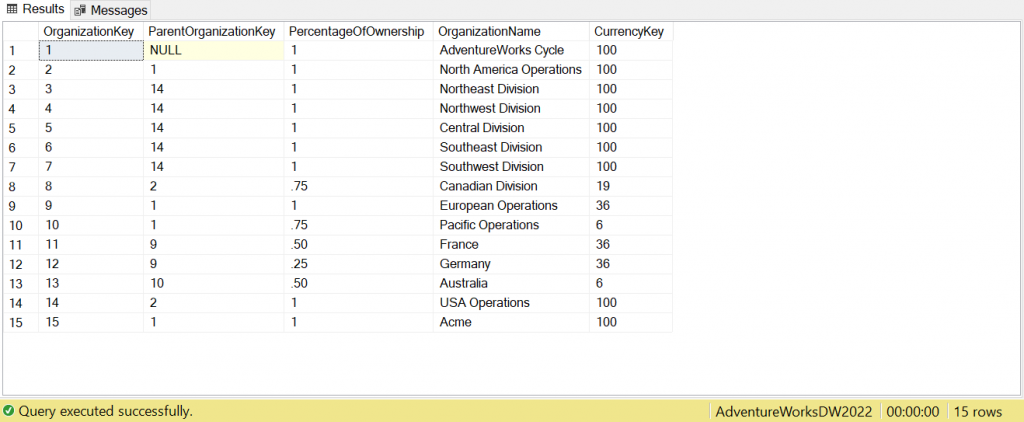
As you can see from the above screenshot, rows 16 and 17 have been deleted and the record with the smallest ‘OrganizationKey’ has been left intact.
Summary
In this post, I have demonstrated an approach that you can take to find and delete duplicate records from a SQL Server or Azure SQL database using T-SQL.
I started by explaining the setup of the test environment and my process for creating some duplicate data to work with.
I then provided a SQL query that you can adapt and use to find records that contain duplicate data within your own databases, to give you confidence that the correct data has been identified for deletion.
Finally, I modified the query slightly to show how the deletion of the duplicate records can be actioned.
Comments